Обновлено 4 апреля 2026
Composer и real-time RL: как Cursor гонит чекпоинты по живым токенам
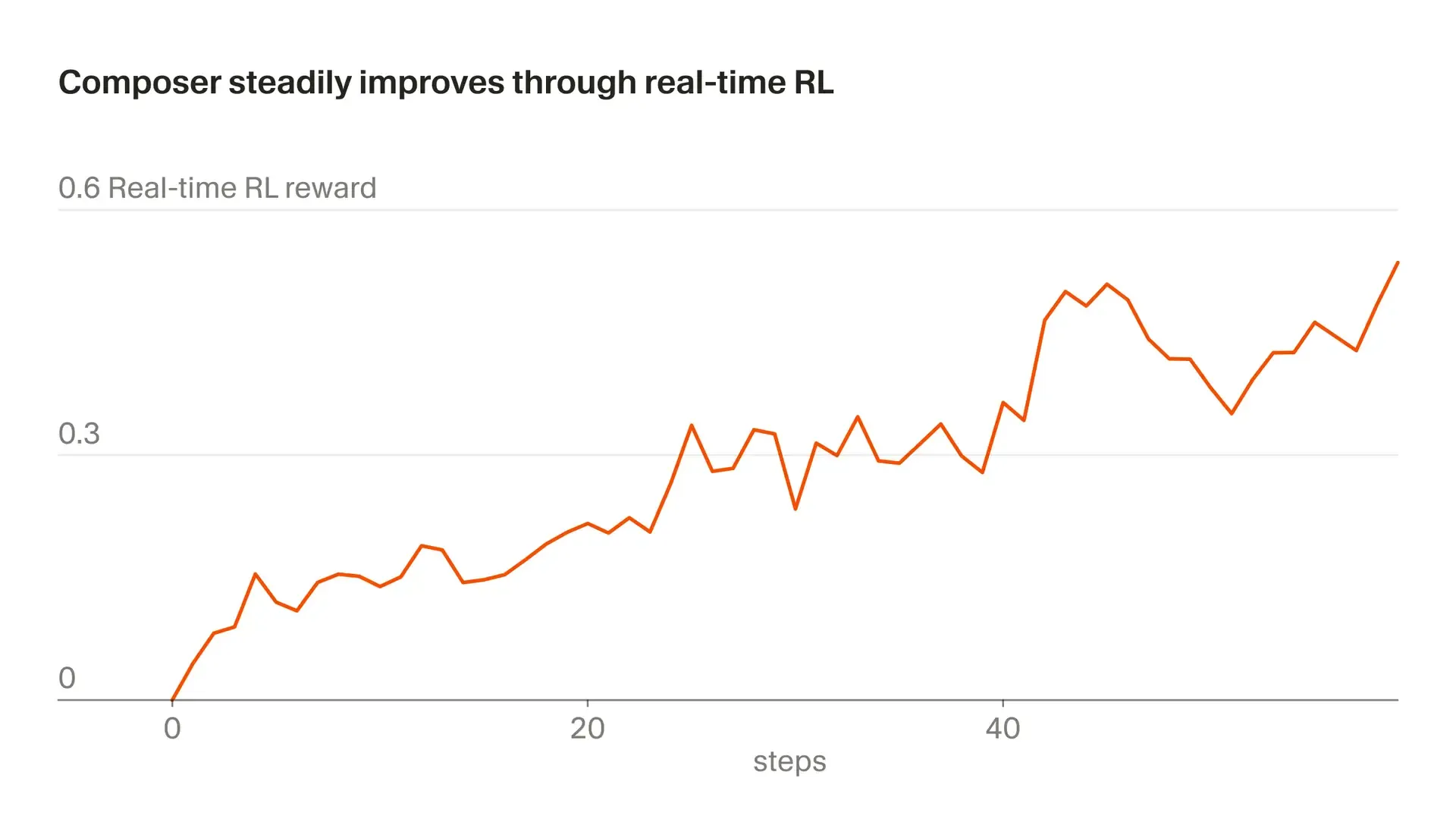
В блоге Cursor [LINK:описали], как к модели Composer подключают онлайн-обучение с подкреплением: свежие чекпоинты уходят в прод, а ответы и действия пользователей в реальных сессиях складывают в сигнал награды. Так команда обозначает подход «real-time RL» — попытку брать обучающий сигнал из тех же токенов инференса, которых в проде уже триллионы.
Похожую схему раньше использовали для Tab; теперь её переносят на Composer. Заявленная цель — чаще выкатывать улучшенную версию за агента в режиме Auto, вплоть до обновлений порядка раза в несколько часов — без ожидания отдельного «большого» релиза модели.
Почему не хватает только «идеальных» синтетических сред? Для кода симулятор среды получается довольно близким к реальности, но прод-сценарий включает ещё и человека, который задаёт направление и принимает решения. Именно пользователя сложнее всего честно смоделировать — отсюда и тяга к сигналу из настоящих диалогов и правок.
В тексте также заходят в риски вроде reward hacking и в планы на более длинные циклы и специализацию — что делать дальше, когда короткий контур RL уже крутится в проде.
Источник: Cursor — Improving Composer through real-time RL