Обновлено 24 июня 2026
Replit Agent оценивают по кликам, не по unit-тестам — 4 слоя
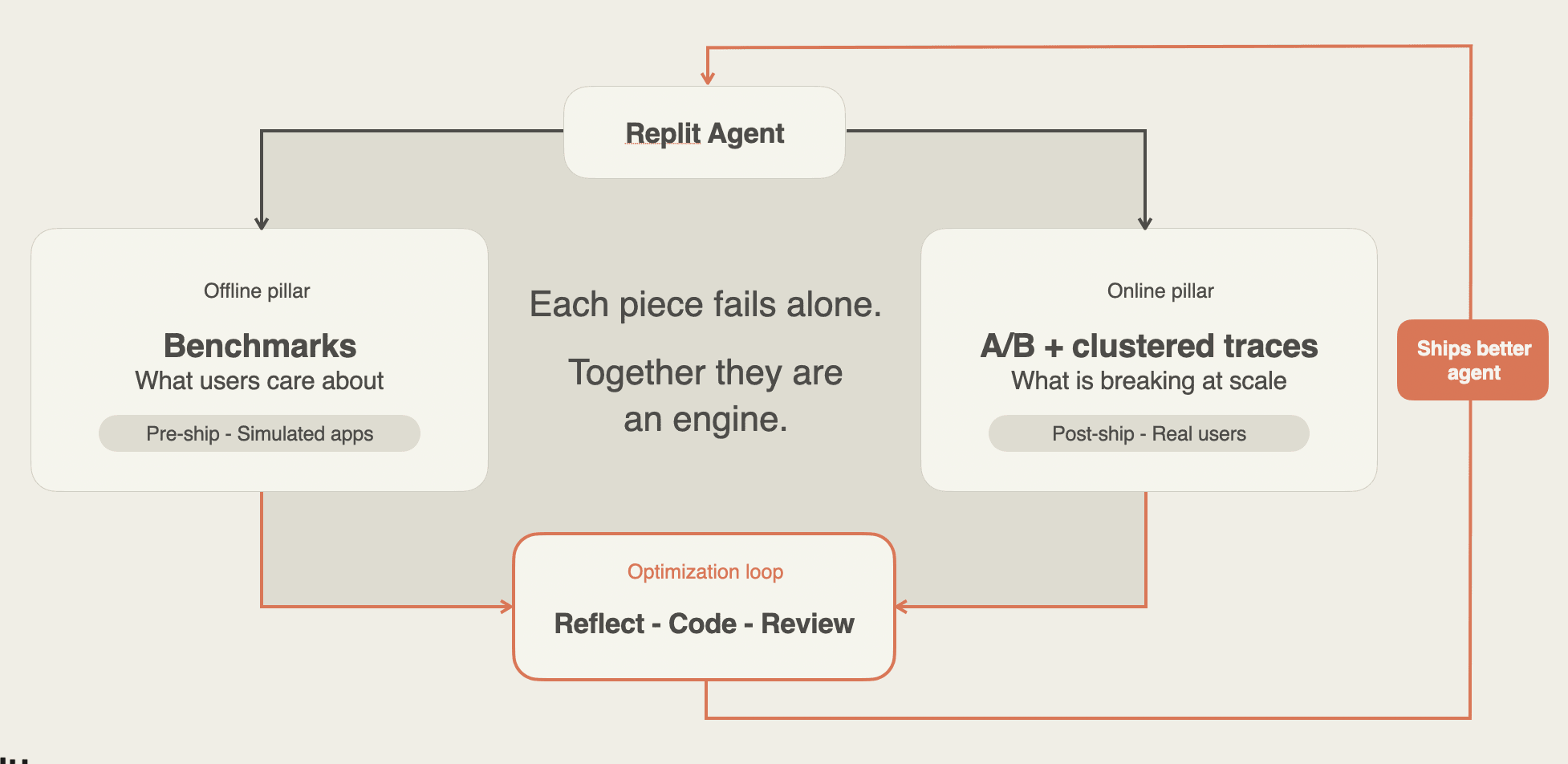
Replit Agent должен просто работать, когда пользователь кликает по интерфейсу — vibe-кодер не спрашивает, прошёл ли patch или unit-тест. Replit замкнула цикл улучшения агента: оценка встроена в продукт, а не живёт отдельным отчётом.
Запрос часто начинается с идеи на естественном языке — без репозитория, тестового набора и выбранного фреймворка. На выходе может быть сайт, слайды, мобильное приложение или несколько связанных артефактов. Модели, промпты, тулы и интерфейсы меняются week over week, и команде нужна уверенность, что каждый релиз реально улучшает опыт для таких сценариев.
Четыре части системы
Оценка не должна выдавать только балл — она показывает, что важно пользователям, где ломается пайплайн и какие изменения имеет смысл выкатывать следующими. Replit выделила четыре звена, которые замыкают путь от сбоя до патча.
- ViBench — офлайн end-to-end оценка до продакшена.
- A/B-тесты — замеры поведения в production после релиза.
- Telescope — разбор trace и кластеризация типовых сбоев.
- Optimization loop — превращение evidence в кандидаты на апдейты.
ViBench ловит регрессии до того, как пользователь увидит новую версию; A/B-тесты подтверждают эффект на живом трафике. Telescope группирует похожие trace, чтобы не чинить одну и ту же ошибку под разными симптомами. Optimization loop переводит кластеры в конкретные правки промптов, тулов и UI.
Для соло-разработчика с vibe coding тот же принцип: если успех — «работает под моим запросом при кликах», то offline-бенч, трассировка и прод-эксперименты полезнее, чем формальный зелёный CI. Замкнутый цикл — это не leaderboard ради leaderboard, а более быстрый путь от реального провала до релиза, который его закрывает.
Источник: Closing the loop: Evaluating and improving Replit Agent at scale.