← Назад к AI Vibe News
Обновлено 4 апреля 2026
Replit учит свои LLM: Databricks, Hugging Face и MosaicML
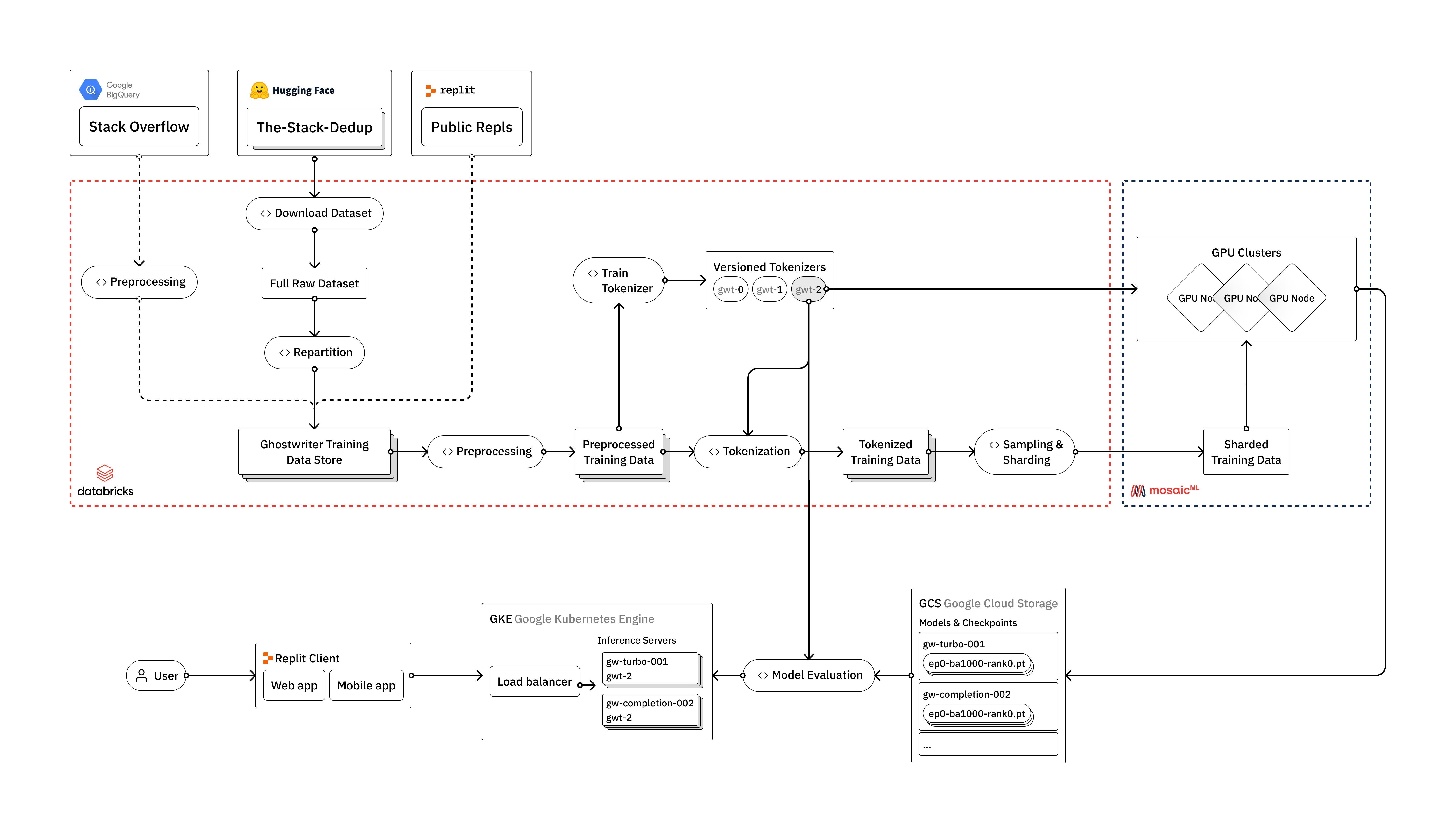
Обучение больших языковых моделей обычно ассоциируется с OpenAI, Google и другими гигантами. Replit показывает, что свой LLM можно собрать и без их бюджета — на стеке Databricks, Hugging Face и MosaicML.
Команда описывает полный цикл: от сырых данных до продакшена. Основной фокус — модели для генерации кода, но подход применим и к общим языковым моделям. В блоге разбирают инженерные вызовы и то, как выбирают вендоров под современный LLM-стек.
Если интересно, как устроено обучение моделей «под капотом» и какие инструменты реально используют в проде — в материале есть обзор и обещание серии постов с деталями.
Источник: How to train your own Large Language Models (Replit Blog)